OpenAI o1 atau LLM Strawberry, AI Model Setara PhD

Belum lama ini, OpenAI baru saja merilis o1, juga dikenal sebagai Project Strawberry. Ini adalah level baru AI yang dapat "berpikir" dan "bernalar" sebelum merespons. 10 demo menariknya antara lain :
1. Coding Video Game from a prompt
2. Fisika Kuantum
3. Answering Famously tricky questions for AI
4. Reasoning
5. Economics
6. Solving complex logic puzzle
7. Genetics
8. Translates corrupted sentences
9. Math
10. Coding
Model o1 atau LLMs Strawberry ini menarik perhatian karena kemampuan penalarannya yang jauh lebih baik dibandingkan model sebelumnya. Salah satu kunci di balik peningkatan kemampuan ini adalah penggunaan reasoning tokens. Untuk memahami cara kerja model ini, mari kita bahas secara lebih rinci di artikel ini.
Apa itu Reasoning Tokens?
Dalam konteks LLM, tokens adalah unit terkecil dari teks yang dapat diproses oleh model. Reasoning tokens bekerja dengan cara memecah prompt menjadi langkah-langkah yang lebih kecil dan lebih mendetail.
Reasoning tokens adalah jenis token khusus yang digunakan oleh model untuk melakukan proses berpikir atau penalaran. Ketika diberikan sebuah pertanyaan atau permintaan, model tidak hanya langsung menghasilkan jawaban, tetapi juga akan menghasilkan reasoning tokens untuk membantu memahami pertanyaan secara mendalam.
Prosesnya ini bisa diibaratkan seperti manusia yang berpikir sebelum menjawab. Kita tidak langsung memberikan jawaban saat ditanya, tetapi akan mencoba memahami pertanyaannya terlebih dahulu, mempertimbangkan berbagai kemungkinan jawaban, dan baru kemudian memberikan jawaban yang paling relevan.
Proses Penalaran Model dalam Percakapan
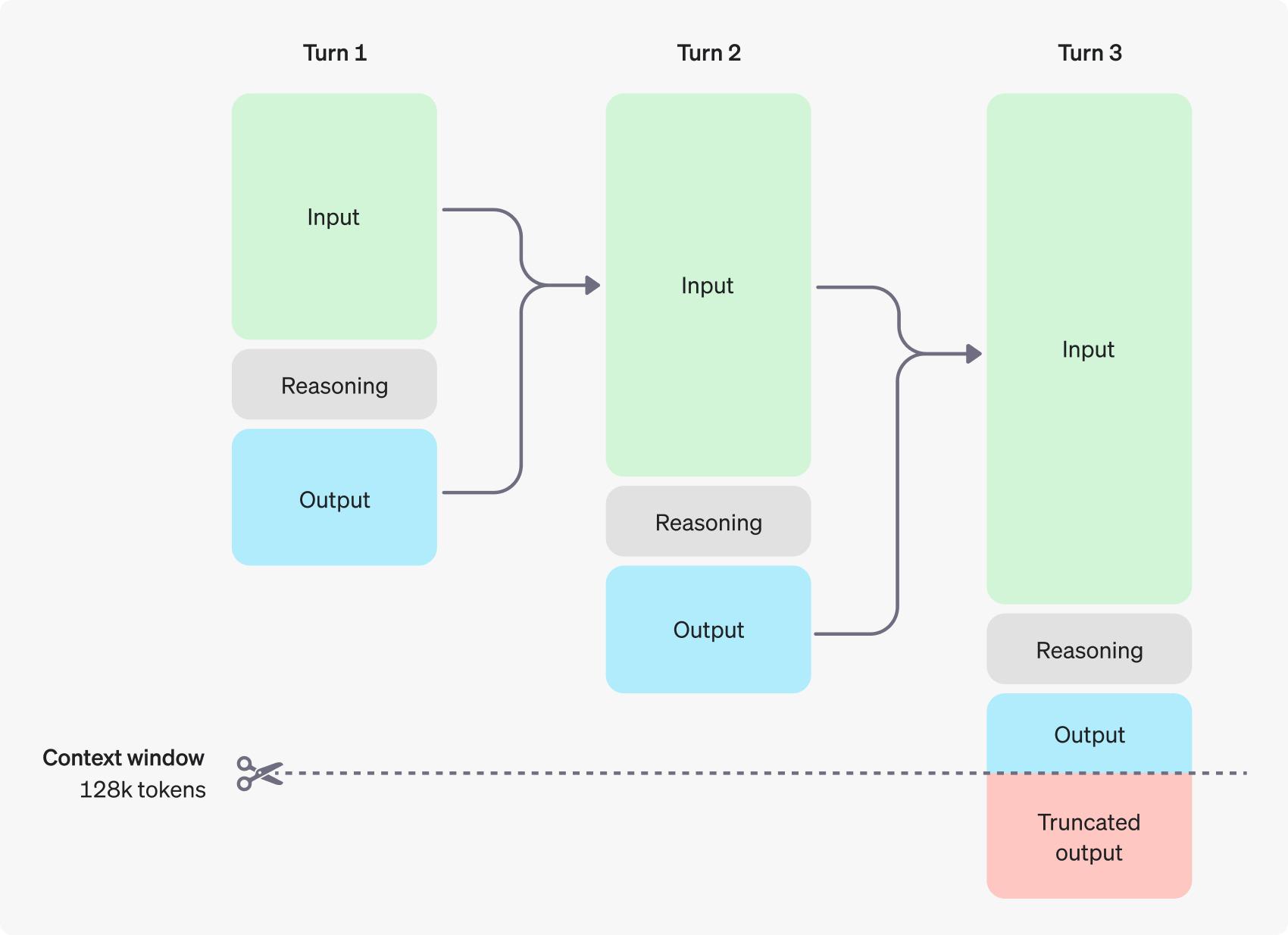
Pada gambar di atas, kita dapat melihat contoh percakapan multi-step antara pengguna dan AI. Setiap percakapan terdiri dari tiga elemen utama: Input, Reasoning, dan Output. Berikut penjelasan lebih lanjut tentang proses tersebut:
Turn 1: Model menerima input dari pengguna, memprosesnya menggunakan reasoning tokens, dan menghasilkan keluaran. Reasoning tokens digunakan untuk membantu model menyusun logika sebelum memberikan respons, namun kemudian dibuang.
Turn 2: Input dari percakapan sebelumnya dibawa ke tahap ini. Model kembali menggunakan reasoning tokens untuk memproses konteks baru sebelum menghasilkan jawaban yang relevan. Output disimpan, sedangkan reasoning tokens kembali dibuang.
Turn 3: Percakapan berlanjut dengan langkah yang sama. Model memproses input dan konteks yang sudah ada, menghasilkan reasoning tokens untuk memahami konteks lebih baik, dan memberikan keluaran. Pada titik ini, apabila jumlah token melebihi batas maksimum (128k tokens), output dapat dipotong atau truncated.
Large Language Models Strawberry: Generasi Baru OpenAI

Selain model o1, OpenAI juga memperkenalkan LLM Strawberry sebagai inovasi dalam teknologi Large Language Models. Model ini dirancang untuk meningkatkan kapabilitas penalaran dan pemahaman terhadap konteks percakapan yang lebih kompleks. Salah satu peningkatan utamanya adalah kemampuannya dalam mengelola multi-step conversation yang lebih mendalam dan mempertahankan konteks dari interaksi sebelumnya tanpa kehilangan detail penting.
LLM Strawberry, bersama dengan o1, menawarkan peningkatan dalam hal efisiensi penggunaan memori dan waktu pemrosesan. Penggunaan reasoning tokens memungkinkan model untuk lebih efisien dalam menghasilkan jawaban, tanpa perlu menyimpan semua data reasoning yang tidak diperlukan lagi setelah respons diberikan.
Reasoning Models OpenAI o1 Setara PhD

Selain o1 dan LLM Strawberry, OpenAI juga memperkenalkan reasoning models dalam tahap Beta, yang secara khusus dirancang untuk melakukan penalaran yang kompleks. Model-model ini dilatih menggunakan reinforcement learning untuk menyelesaikan masalah yang membutuhkan penalaran tingkat tinggi.
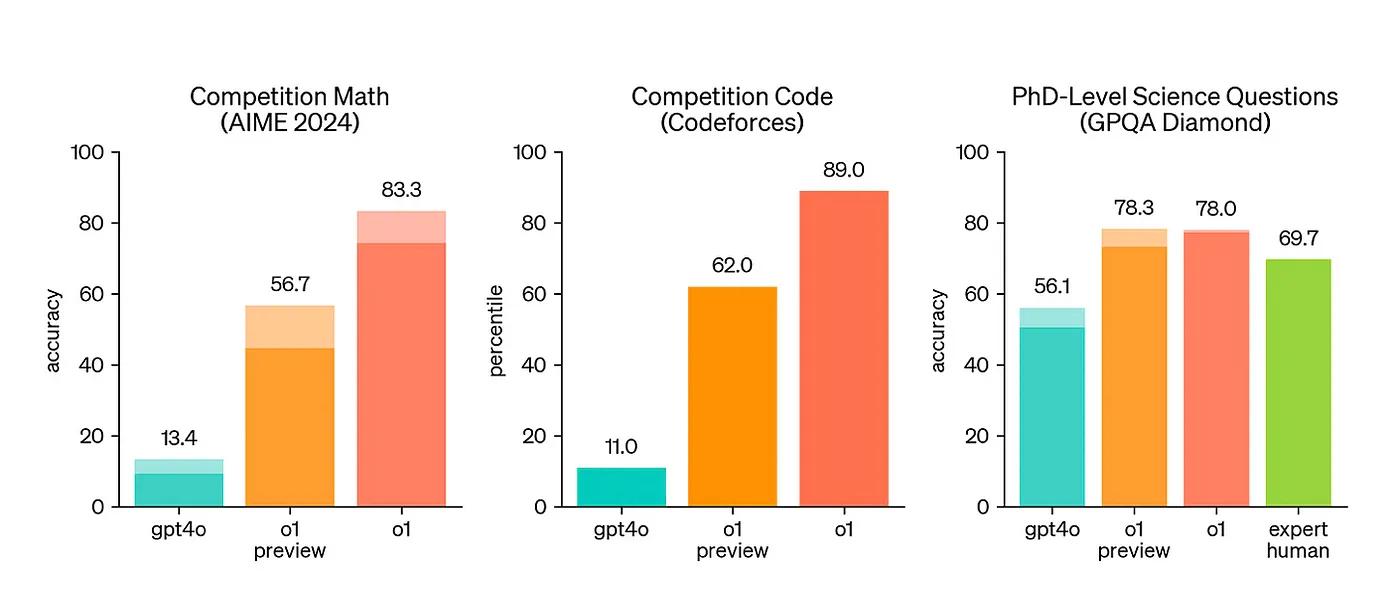
Model o1 telah menunjukkan kinerja yang luar biasa dalam penalaran ilmiah. Misalnya, model ini berada di peringkat 89 persen teratas dalam pertanyaan competitive programming (Codeforces), masuk dalam 500 besar siswa dalam kualifikasi Olimpiade Matematika AS (AIME), serta melampaui akurasi manusia dengan tingkat PhD dalam benchmark yang mencakup masalah fisika, biologi, dan kimia (GPQA).
Terdapat dua versi model reasoning yang tersedia dalam API :
o1-preview
Versi awal dari model o1, dirancang untuk menyelesaikan masalah dengan menggunakan pengetahuan umum yang luas tentang segala hal di dunia.
o1-mini
Versi yang lebih cepat dan lebih murah dari o1, yang unggul dalam tugas seperti pemrograman, matematika, dan sains, tanpa memerlukan pengetahuan umum.
Perlu kita ingat! Model o1 menawarkan peningkatan yang signifikan dalam penalaran, tapi bukan untuk menggantikan GPT-4o dalam semua kasus penggunaan.
Untuk aplikasi yang membutuhkan input gambar atau respons yang cepat dan konsisten, model GPT-4o dan GPT-4o mini tetap menjadi pilihan yang tepat. Namun, jika Anda ingin mengembangkan aplikasi yang membutuhkan penalaran mendalam dan dapat menerima waktu respons yang lebih lama, model o1 bisa menjadi pilihan yang sangat baik.
Kesimpulan
Pengenalan reasoning tokens dalam OpenAI o1 dan LLM Strawberry, bersama dengan reasoning models Beta, merupakan terobosan signifikan dalam teknologi LLM. Dengan memecah proses berpikir model menjadi langkah-langkah kecil, model dapat mempertimbangkan berbagai pendekatan sebelum menghasilkan respons, menghasilkan jawaban yang lebih akurat dan relevan.
Inovasi ini tidak hanya membantu meningkatkan efisiensi model, tetapi juga memberikan pengalaman pengguna yang lebih baik dalam interaksi multi-step.
Dengan adanya fitur-fitur ini, model seperti OpenAI o1 dan LLM Strawberry diharapkan dapat semakin memajukan bidang artificial intelligence (AI) dan natural language processing (NLP), khususnya dalam aplikasi percakapan dan analisis data.
- Webinar Natural Language Processing untuk Twitter Text Analysis
- Playback Webinar Unlocking the Power of AI: GPT, Whisper and DALL-E
- Pelatihan Data Analysis with Python
- Pelatihan Deep Learning Python
- Pelatihan Data Science with Python
Silakan konsultasikan kebutuhanmu dengan kami, klik link https://bit.ly/kontaksuhu

